论文阅读笔记:GaFaR
一篇人脸三维模板反演论文的阅读笔记
论文题目:Template Inversion Attack against Face Recognition Systems using 3D Face Reconstruction
摘要
人脸识别系统在不同应用中越来越普及。在这样的系统中,从每张面部图像中提取某些特征(也称为嵌入或模板)。然后,在注册阶段将提取的模板存储在系统的数据库中,并在后来的识别中使用。在本文中,我们专注于针对人脸识别系统的模板反演攻击,并介绍了一种新方法(称为 GaFaR),以从面部模板重建3D面部。为此,我们使用基于生成性神经辐射场(GNeRF)的几何感知生成网络,并学习从面部模板到生成网络中间潜在空间的映射。我们采用半监督学习方法,同时使用真实和合成图像来训练我们的网络。对于真实训练数据,我们使用基于生成对抗网络(GAN)的框架来学习潜在空间的分布。对于合成训练数据,我们拥有真实的潜在代码,我们直接在生成网络的潜在空间中训练。此外,在推理阶段,我们还提出对相机参数进行优化,以生成面部图像,以提高攻击成功率(在我们的实验中高达17.14%)。我们在LFW和MOBIO数据集上,对最先进面部识别模型的白盒和黑盒攻击中评估了我们方法的性能。据我们所知,这篇论文是首次从面部模板进行3D面部重建的工作。
笔记
动机:人脸识别系统通过提取面部特征(模板)进行注册和识别。本文介绍了一种名为GaFaR的新型模板反演攻击方法,用于从面部模板重建3D面部进行攻击。
模型构造:GaFaR使用基于GNeRF的几何感知生成网络,通过半监督学习训练,结合真实和合成图像。在推理阶段,通过优化相机参数来提升攻击成功率。
- 真实图像使用GAN框架学习潜在空间分布,合成图像直接在潜在空间训练。
项目页面可在 https://www.idiap.ch/paper/gafar 上找到。
一、引言
自动人脸识别(FR)已成为众所周知的生物特征认证工具,已广泛应用于不同的应用中,包括智能手机锁、边境管制等。在此类系统中,通常会包含一些特征(也称为面部嵌入或面部模板) 在注册阶段从用户中提取并存储在系统的数据库中。 在识别阶段,无论是验证还是识别,都会从用户中提取相似的特征,并与系统数据库中的特征进行比较。 因此,面部特征在自动人脸识别系统中发挥着主要作用,传递着用户的重要信息。
针对 FR 系统的模板反演(TI)攻击是指攻击者尝试根据系统数据库中存储的模板重建人脸图像。 然后,攻击者可以找到有关注册用户的敏感信息,也可以使用重建的面部图像来冒充并进入系统。 因此,与大多数威胁系统安全的FR系统攻击相比[19,3,22,18,35,34,10],TI攻击同时危害用户的安全和隐私,因此需要进一步研究。 在本文中,我们介绍了一种用于 FR 系统中的 TI 攻击的新颖方法(称为几何感知面部重建,简称 GaFaR),以根据面部特征(从 2D FR 模型中提取)重建 3D 面部。 3D人脸重建比2D人脸重建提供了更多的信息,特别是可以用来生成任意姿势的人脸图像,以改善对FR系统的攻击。 据我们所知,这是第一篇关于从面部模板进行 3D 面部重建的论文。
最近,神经辐射场(NeRF)[38]由于在新颖视图合成问题上取得了显着的成果,引起了计算机视觉界的广泛关注。 基于 NeRF 的生成 NeRF (GNeRF) 方法,如 [37, 44, 56, 6, 8, 41, 42, 20, 55, 7, 12, 48, 43] 将条件 NeRF 与生成模型相结合,以生成几何感知图像 生成任务。 在这些方法中,生成模型(例如生成对抗网络(GAN))用于将对象的形状和外观嵌入到潜在空间中。 然后,GAN 的潜在代码与相机参数一起被馈送到 NeRF 进行渲染过程。 在GNeRF方法中,有一些用于几何感知3D人脸生成的工作,例如[8,41,42,20,55,7,12,48],它们可以从不同的视角生成人脸图像。
在我们提出的 TI 方法中,我们使用基于 GNeRF 的几何感知面部生成器网络,并学习从面部模板到生成器网络的中间潜在空间的新映射。 我们使用真实图像和合成图像以及半监督学习方法同时训练我们的网络。 对于没有相应潜在代码(即无监督)的真实训练数据,我们使用基于 GAN 的框架来学习潜在空间的分布。对于具有潜在代码真实值(即监督)的合成训练数据,我们直接学习潜在空间。 因为我们有 3D 重建的脸部,所以我们可以使用任意姿势来注入 FR 系统进行攻击。 因此,在推理阶段,我们还利用相机参数的优化来提高对FR系统的攻击。 我们评估了我们提出的方法在白盒(即,对手知道 FR 模型的内部功能和参数)和黑盒(即,对手不知道有关 FR 模型的内部功能的信息)攻击中的性能 对抗最先进的 (SOTA) FR 系统。 为了进行评估,我们考虑具有 LFW [23] 和 MOBIO [36] 数据集的 FR 系统,并评估我们的攻击是否可以使用重建的人脸进入系统。 图 1 展示了来自 FFHQ [26] 数据集的样本人脸图像以及使用我们的攻击从 ArcFace [11] 模板中进行的 3D 重建。

为了详细阐述本文的贡献,我们将其列出如下:
- 我们提出了一种新颖的模板反演方法,用于根据人脸识别系统的面部模板重建 3D 人脸。 据我们所知,这篇论文是第一篇关于从面部模板进行 3D 面部重建的工作。
- 我们使用基于GNeRF 的几何感知生成器网络(geometry-aware generator network),并学习从面部模板到生成器网络的中间潜在空间的映射。 我们使用基于 GAN 的框架和使用真实和合成面部图像的半监督学习方法来训练我们的映射网络。
- 我们在推理阶段对几何感知生成器网络中的相机参数进行优化。 相机参数的优化可以找到提高攻击成功率的姿势。
二、相关工作
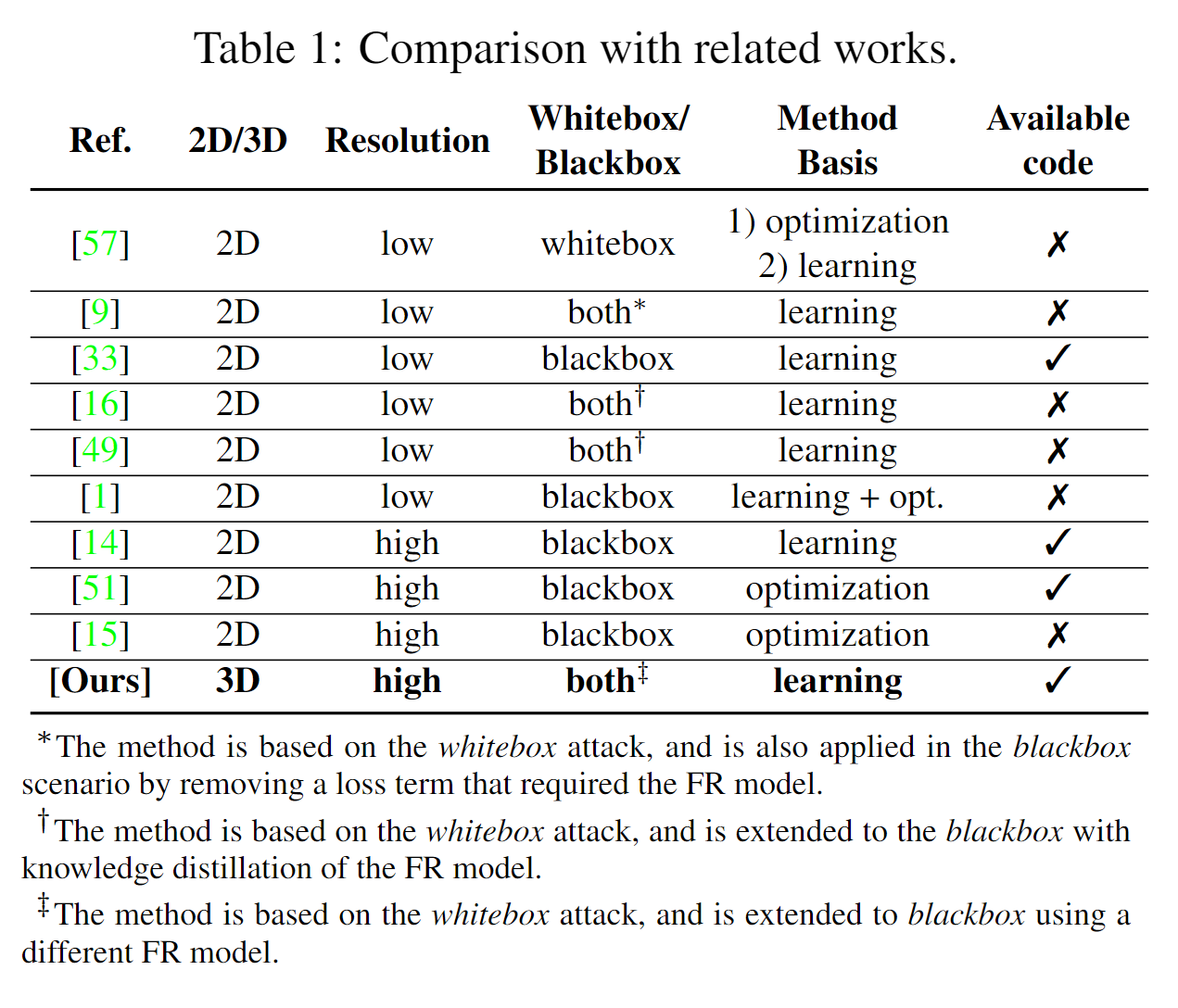
一般来说,文献中从面部模板重建面部的方法生成二维面部图像。 在[57]中,作者提出了两种基于优化和学习的方法,在白盒场景下从面部模板重建二维低分辨率面部图像。在基于优化的方法中,他们使用基于梯度上升的算法来重建人脸图像,并优化生成的图像以最小化多项损失函数,包括目标模板与重建人脸图像模板之间的ℓ2(欧几里得)距离。 此外,他们在重建图像上应用了全变分和拉普拉斯金字塔梯度归一化[5]以生成平滑图像。 在基于学习的方法中,他们使用反卷积神经网络来重建面部图像,并使用与基于优化的方法中使用的相同损失函数对其进行训练。
在[9]中,训练多层感知器(MLP)从给定模板中查找面部标志坐标(使用均方误差进行优化)。 他们还训练了一个卷积神经网络 (CNN),以根据目标模板生成面部纹理(使用平均绝对误差进行优化)。 然后,他们使用可微扭曲来结合估计的坐标(来自 MLP)和纹理(来自 CNN)并重建低分辨率面部图像。 在白盒场景中,他们通过最小化重建人脸图像模板与原始人脸图像之间的距离,进一步优化了 MLP 和 CNN。 然而,在黑盒场景中,他们分别训练 MLP 和 CNN,并且仅在推理中使用扭曲。
在文献[33]中,提出了两种新的反卷积网络,分别称为NbBlock-A和NbBlock-B。这些网络通过像素损失(重建误差的ℓ1范数)和感知损失(给出重建和原始面部图像时VGG-19[46]中间层的距离)进行训练,以在黑盒场景中重建低分辨率的面部图像。在文献[16]和[49]中,使用了一种基于双射学习的相同方法分别训练具有PO-GAN[25]和TransGAN[24]结构的GAN模型。该方法基于白盒攻击,并且在训练GAN模型时,作者还最小化了目标模板与使用面部识别(FR)模型从重建面部图像中提取的模板之间的距离。在黑盒攻击中,他们提议使用知识蒸馏来训练一个模仿目标FR模型的学生网络,并将该学生网络用于他们的方法中。然而,他们并没有报告有关学生网络训练的任何细节(例如,网络结构等),也没有发布源代码。
在[1]中,提出了一种三步方法来重建黑盒场景中的低分辨率人脸图像。 首先,他们训练了一个用于一般面部生成的 GAN。 第二步,他们训练 MLP 将目标模板映射到已知 FR 模型的嵌入。 在最后一步中,他们在生成器(GAN)的输入中发现了一个潜在代码,该代码生成一个最大化两项的面部图像; 鉴别器得分(作为真实的人脸图像)以及映射嵌入和已知 FR 模型提取的嵌入之间的余弦相似度。
与文献中大多数生成低分辨率人脸图像的作品相比,最近很少有生成高分辨率2D人脸图像的作品。 在[51]中,使用模拟退火[50]方法的网格搜索优化被用于StyleGAN2[28]的潜在向量(即输入噪声),以找到可以生成人脸图像的潜在代码,这些代码具有与 目标模板。 然而,他们提出的方法计算成本很高,而且他们仅报告了对 20 张人脸图像的评估。 在[15]中,考虑了对StyleGAN2[28]的潜在向量进行与[51]类似的优化,但它是使用标准遗传算法[47]来解决的。 与基于优化的[51, 15]相比,[14]在黑盒场景中提出了一种基于学习的方法。 作者提出使用 StyleGAN2 [28] 生成一些人脸图像,并使用 FR 模型提取模板。 然后,他们训练 MLP 将面部模板映射到 StyleGAN2 [28] 的输入潜在代码。
表1 将我们提出的方法与文献中的先前工作进行了比较。据我们所知,我们提出的方法是从2D面部识别模型中提取的面部模板进行3D面部重建的首次工作。此外,与文献中的大多数工作不同,我们的方法生成的是高分辨率面部图像。最后但同样重要的是,我们的方法可以用于对面部识别系统的白盒和黑盒攻击。
*三、提出的方法
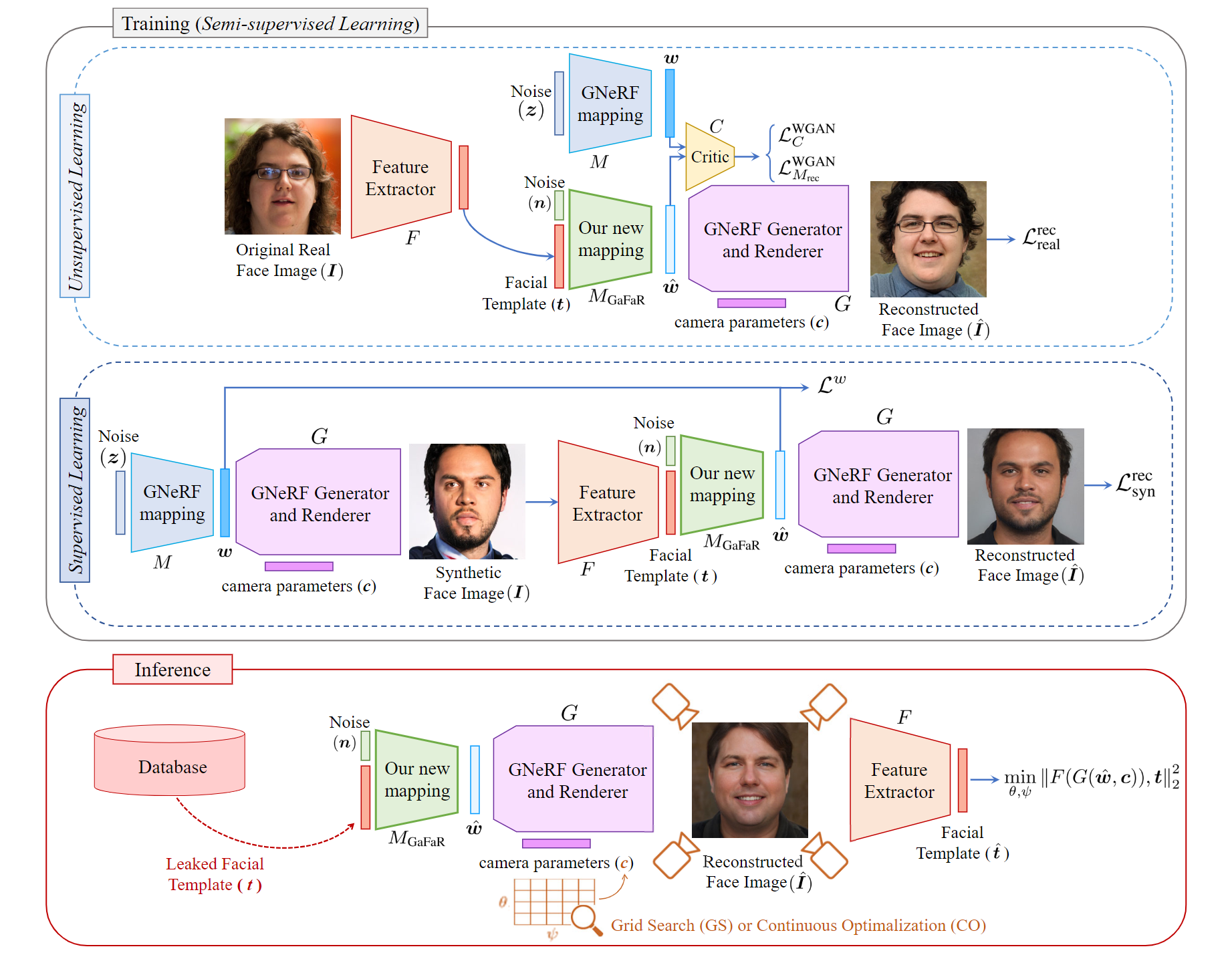
在本文中,我们考虑了第 2 节中描述的威胁模型。 3.1 并使用第 2 节中描述的建议的 3D 人脸重建方法(称为 GaFaR)。 3.2. 训练后和推理阶段,我们对相机参数进行优化,如第 2 节中所述。 3.3 生成具有可以导致更高成功攻击率(SAR)的姿势的2D人脸图像并将人脸图像注入到系统中。 图 2 描述了所提出方法的框图。
3.1 威胁模型
我们考虑的是对面部识别(FR)系统的攻击场景,其中攻击者能够访问到系统的数据库,并企图生成注册用户的3D面部重建图像。为此目的,攻击者训练了一个网络,该网络能够根据给定的目标面部模板重建出3D面部。接着,攻击者可以利用这个3D面部重建图像来伪装成系统中的用户(例如,通过使用3D面部面具等手段)。为了简化问题,我们假设攻击者可以将一个2D面部图像(从3D重建的面部获得)注入到系统中。因此,攻击者会采用适当的姿势生成用于攻击的2D面部图像。根据攻击者对FR模型了解程度的不同,我们考虑了白盒和黑盒两种攻击场景。在白盒场景中,我们假定攻击者对FR模型有完全的了解,也就是模板泄露的来源模型。然而,在黑盒场景中,我们假定攻击者并不知道FR模型的内部工作机制,只能利用FR模型为任何面部图像生成面部模板。此外,我们还假设在黑盒场景中,攻击者可以接触到另一个FR模型,并且知道其内部参数和工作方式。
笔记
攻击者可能对系统数据库进行的访问,并尝试通过训练网络来重建注册用户的3D面部图像。攻击者可以利用这个3D重建来系统中冒充用户,例如使用3D面部面具。文中区分了两种攻击场景:
白盒攻击:攻击者对FR系统模型有完全了解,包括模型的内部结构和参数,能够直接利用这些信息进行攻击。
黑盒攻击:攻击者对FR系统模型的内部工作原理不了解,只能通过模型提供的接口生成面部模板。但假设攻击者可以访问另一个已知的FR模型,并了解其内部参数和功能,这为攻击提供了一定程度的信息支持。
在这两种情况下,攻击者的目标都是生成一个2D面部图像,该图像在攻击中使用,并根据需要调整图像的姿势以最大化攻击成功的可能性。
3.2 三维面部重建
总览
为了从面部模板中重建三维面部,我们采用了基于GNeRF(生成性神经辐射场)的几何感知面部生成网络,例如EG3D[7],并学习了一个映射\(M_{GaFaR}\):将面部模板t从集合T映射到GNeRF模型的中间潜在空间W( \(T → W\) )。
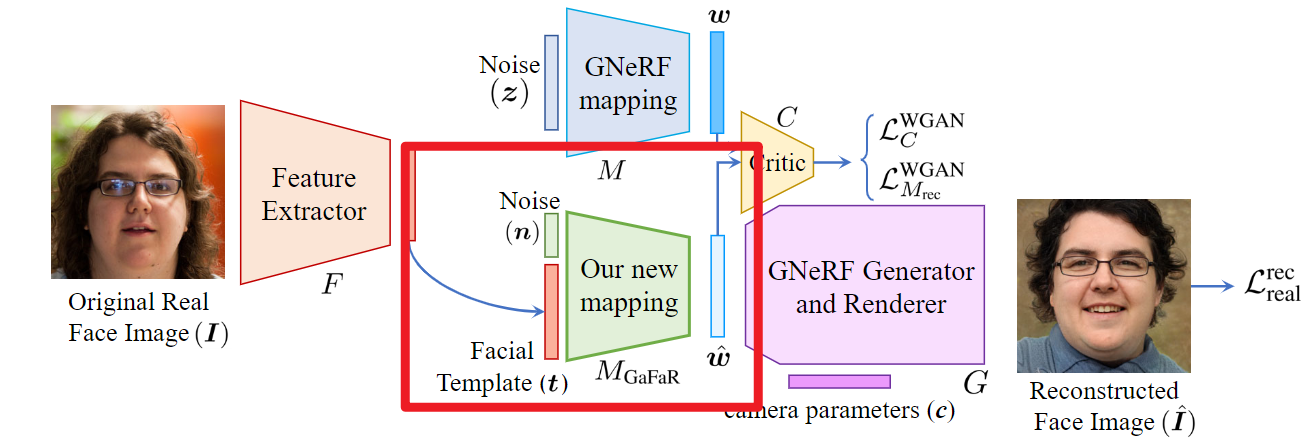
接着,我们利用GNeRF模型的其余部分\(G(·)\)来合成图像 \(\hat{I} = G(\hat{w}, c)\),这个过程使用映射后的中间潜在向量 \(\hat{w}\)和相机参数\(c\),从任意视角生成图像。
我们为映射网络\(M_{GaFaR}\)设计了一个包含两个全连接层的网络,这些层采用了Leaky ReLU激活函数。
我们采用半监督方法训练映射网络\(M_{GaFaR}\),这种方法结合了合成数据和真实数据。
GNeRF(GAN-based Neural Radiance Field)模型
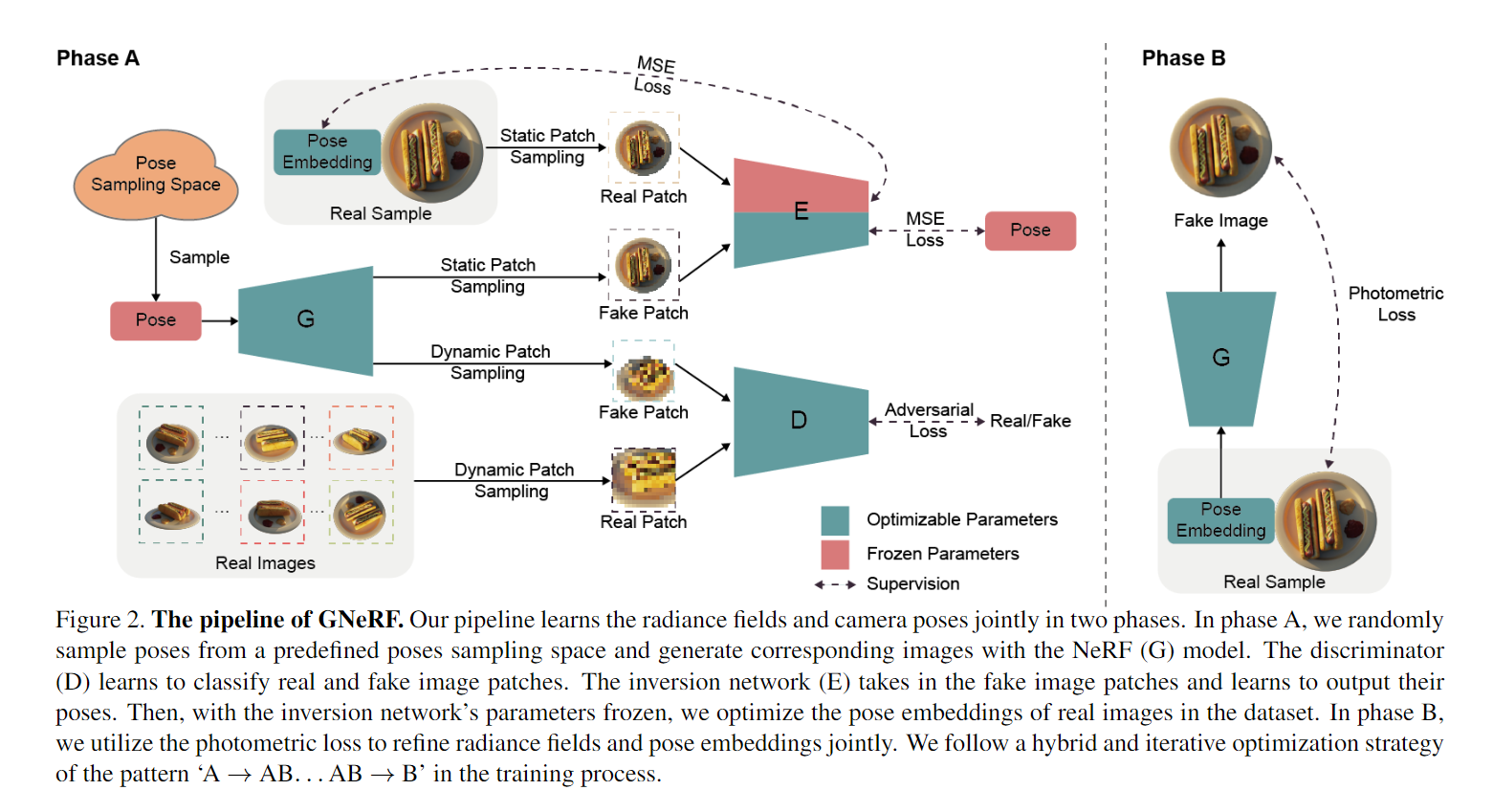
GNeRF(GAN-based Neural Radiance Field)模型是一个结合了生成对抗网络(GAN)和神经辐射场(NeRF)的框架,专门设计用于在相机姿态未知的情况下重建复杂场景。
- 模型结构:
- 生成器(Generator G):负责从随机初始化的相机姿态合成图像,通过查询神经辐射场并执行体积渲染。
- 判别器(Discriminator D):用于区分真实图像块和生成器产生的图像块。
- 反演网络(Inversion Network E):将图像块映射回相机姿态,用于在没有准确相机姿态的情况下预测姿态。
- 阶段意义:
- 阶段A(Pose-free NeRF Estimation):无姿态的NeRF估计阶段。在这个阶段,模型不依赖于准确的相机姿态估计,而是通过对抗学习来预测每张图像的大致姿态并学习场景的粗糙辐射场。生成器和判别器进行对抗训练,同时反演网络学习将图像块映射到相应的相机姿态。
- 阶段B(NeRF Refinement):NeRF细化阶段。在获得初始NeRF模型和相机姿态估计后,此阶段通过最小化光度重建误差来优化NeRF模型和相机姿态,提高模型的质量和姿态估计的准确性。
- 正则化学习策略(AB…AB):
- 这是一种交替进行的策略,通过在无姿态NeRF估计和NeRF细化之间迭代,来进一步提高NeRF模型的性能和相机姿态的估计准确性。这种策略基于的观察是,即使在细化步骤中,无姿态NeRF估计也能提供对模型和相机姿态有益的改进。
真实数据
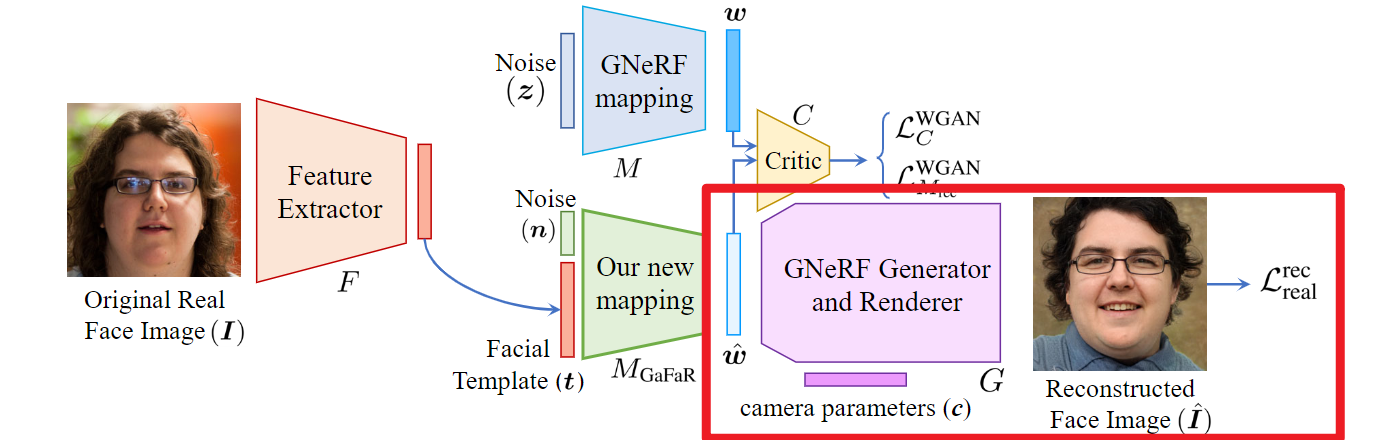
对于真实数据部分,我们选取了一系列真实面部图像集合\({\{I_{real,i}\}}^{N}_{i=0}\),利用面部识别(FR)模型\(F(·)\)从每张真实面部图像 \(I_{real,i}\) 中提取面部模板\(t_{real,i} = F(I_{real,i})\)。因为我们没有\(GNeRF\)模型中间潜在空间W的真实值来生成真实面部图像,所以我们将这些数据用于无监督学习来训练映射网络。
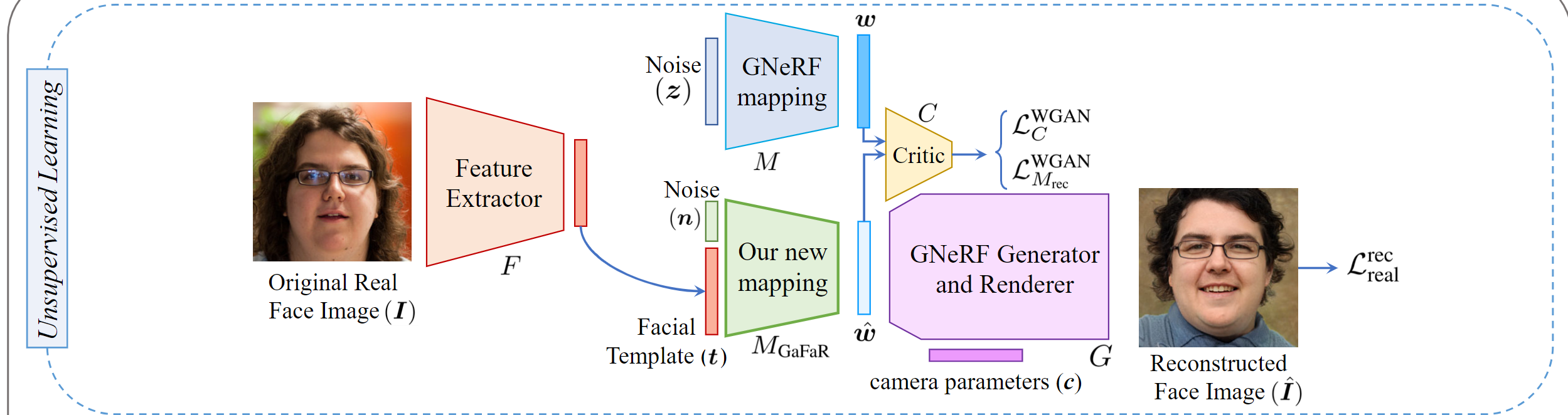
在无监督学习中,我们使用真实数据来训练我们的映射网络\(M_{GaFaR}(.)\)。我们采用基于Wasserstein生成对抗网络(WGAN)算法的GAN框架来学习GNeRF模型中间潜在空间W的分布。
在这个框架中,我们的映射网络MGaFaR生成一个潜在代码 \(\hat{w} = M_{GaFaR}([n, t])\),使用面部模板t和一个随机向量\(n ∈ N\)。我们也可以利用GNeRF映射函数M和一个随机向量\(z ∈ Z\)生成真实的潜在代码\(w = M(z) ∈ W\),来训练我们的GAN。
然后,我们可以使用一个评价网络C(.)来为由我们的映射MGaFaR(.)和GNeRF映射M(.)生成的潜在代码打分。评价网络是一个具有三层的全连接网络,采用Leaky ReLU激活函数。
因此,我们可以使用以下损失函数来训练评价网络C(·)和我们的映射MGaFaR:(WGAN)
\[L^{WGAN}_C = E_{w \sim M(z)}[C(w)] - E_{\hat{w} \sim MGaFaR([n,t])}[C(\hat{w})] \quad (1)\] \[L^{WGAN}_{M_{GaFaR}} = E_{\hat{w} \sim MGaFaR([n,t])}[C(\hat{w})] \quad (2)\]除了WGAN训练外,我们还使用生成的面部图像 \(\hat{I} = G(M_{GaFaR}([n, t]), c)\) 来优化我们的映射网络,使用以下损失函数:
\[L_{rec\_real} = L_{Pixel} + L_{ID} \quad (3)\]其中\(L_{Pixel}\)和\(L_{ID}\)分别是像素损失和ID损失,定义如下:
像素损失: \(L_{Pixel} = E_{\hat{w} \sim MGaFaR([n,t])}[\|I - G(\hat{w}, c)\|^2_2] \quad (4)\) 像素损失衡量重建图像与原始图像在像素级别上的差异。
ID损失: \(L_{ID} = E_{\hat{w} \sim MGaFaR([n,t])}[\|F_{loss}(I) - F_{loss}(G(\hat{w}, c))\|^2_2] \quad (5)\) ID损失确保映射网络生成的面部图像的面部模板与原始图像的面部模板相似,帮助网络生成具有由\(F_{loss}\)提取的类似面部模板的面部图像。
在白盒场景中,计算方程(5)中的ID损失时,我们使用与泄露模板计算相同的FR模型(即\(F\))。然而,在黑盒场景中,我们使用另一个我们假设攻击者可以访问的FR模型。
合成数据
对于合成数据,我们利用预先训练好的几何感知面部生成网络生成了一组随机面部图像集合 \({\{I_{syn,i}\}}^{M}_{i=0}\) 。与真实数据不同,我们对于合成数据拥有中间潜在空间\(w ∈ W\)的真实值,可以用来生成相同的合成面部图像。因此,我们使用合成数据进行监督学习来训练映射网络。
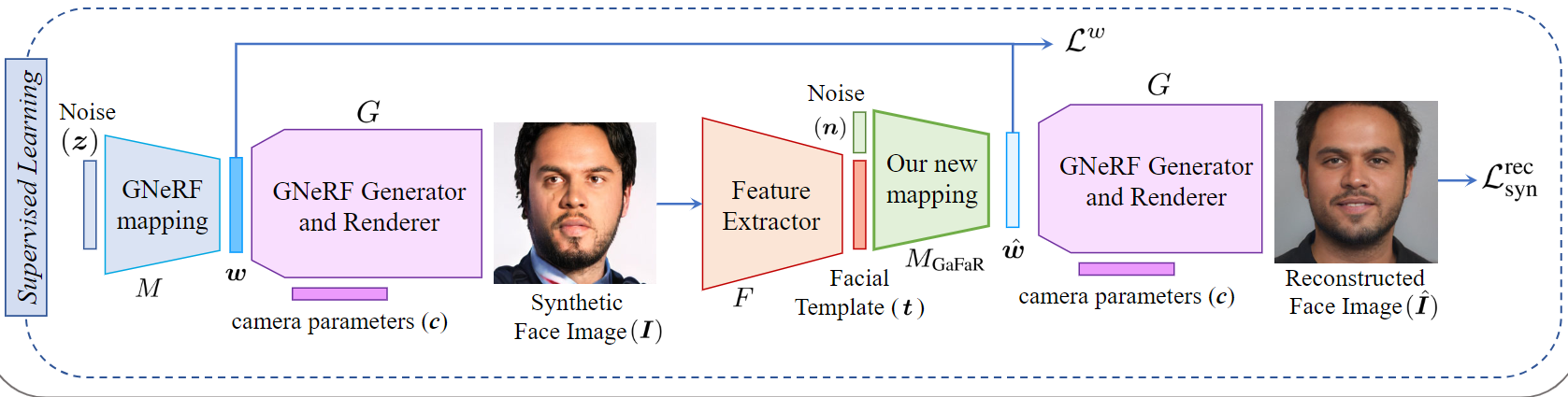
为了使用合成数据训练我们的映射网络\(M_{GaFaR}(.)\),我们可以直接学习GNeRF中间潜在代码\(w = M(z)\)。
除了直接学习\(w\)之外,我们还使用生成的面部图像通过最小化以下多项损失函数来训练我们的映射网络: \(L_{rec\_syn} = L_{w} + L_{Pixel} + L_{ID}\) 其中\(L_{Pixel}\)和\(L_{ID}\)分别是像素损失和ID损失。此外,\(L_w\)是\(w\)损失,通过最小化\(w\)和 \(\hat{w} = M_{GaFaR}([n, t])\)之间的均方误差来直接学习潜在空间,如下所示: \(L_{w} = E_{w \sim M(z)}[\|w - MGaFaR([n, t])\|^2_2]\)
3.3. 相机参数优化
在推理阶段,使用我们在第3.2节中描述的方法生成面部的3D重建之后,我们优化相机参数以找到一个可以增加攻击成功率(SAR)的姿势。在不同的相机参数\(c\)中,与相机旋转相对应的参数可以改变生成的面部图像的姿势。请注意,通过改变相机旋转,我们旨在改变3D重建面部的俯仰(pitch)和偏航(yaw)旋转,而不修改翻滚(roll)旋转。实际上,在FR系统中特征提取之前的面部对齐预处理步骤中,面部的翻滚旋转将被消除。

为了优化相机参数,我们考虑了以下两种不同的方法:
网格搜索(Grid Search):通过预定义的步长来改变相机参数中的俯仰角θ和偏航角ψ,生成所有相机旋转步长值的2D面部图像,并为每个生成的图像找到面部模板。然后,我们选择面部图像\(\hat{I} = G(\hat{w}, c)\),使得其模板\(\hat{t} = F(\hat{I})\) 与目标模板t之间的均方根误差最小。
连续优化(Continuous Optimization):从正面图像开始,使用Adam优化器来解决以下最小化问题
\[\hat{w} = MGaFaR([n, t])\] \[\min_{\theta, \psi} \|F(G(\hat{w}, c)), t\|^2_2\]在这个优化中,我们找到相机旋转参数θ和ψ,使得生成的面部图像的模板接近目标模板t。与网格搜索方法不同,连续优化只能应用于白盒场景(必须知道F)。
四、实验
4.1. 实验装置
人脸识别模型
在我们的实验中,我们考虑了包括ArcFace[11]、ElasticFace[4]在内的多种当前最先进的(State-of-the-Art,简称SOTA)面部识别模型,以及FaceX-Zoo[53]中带有SOTA骨干网络的四种不同的面部识别模型,包括AttentionNet[52]、HRNet[54]、RepVGG[13]和Swin[32]。这些模型的识别性能在补充材料中有所记录。
数据集
所有提到的 FR 模型都是在 MS-Celeb1M 数据集 [21] 上训练的。 为了训练人脸重建网络,我们假设对手对训练 FR 模型所使用的数据集没有任何了解,并使用不同的数据集。 为此,我们考虑使用 FlickrFaces-HQ (FFHQ) 数据集 [27],该数据集包含从互联网爬取的 70,000 张高质量图像(没有身份标签),用于训练我们的人脸重建网络。 我们将 FFHQ 随机分为训练集 (90%) 和测试集 (10%)。
为了评估 FR 模型的脆弱性,我们使用了另外两个数据集,包括 Labeled Faces in the Wild (LFW) [23] 和 MOBIO [36] 数据集。 LFW 数据集包含从互联网收集的 5,749 人的 13,233 张人脸图像,其中 1,680 人拥有两张或更多图像。 MOBIO 数据集包括使用移动设备在每个人 12 个会话中捕获的 150 人的面部图像。
评估协议
为了对每个 LFW 和 MOBIO 数据集进行评估,我们构建了一个单独的 FR 系统,并使用参考模板(即注册到系统的数据库中)作为我们的面部重建方法的输入。 然后,我们将重建的人脸图像作为查询注入到系统中,并评估对手进入FR系统的攻击成功率(SAR)。 我们应该注意到,对于每张图像,我们仅使用一张重建的人脸图像作为对 FR 系统的查询并评估 SAR。
实现细节和源代码
在我们的实验中,我们在推理阶段使用了网格搜索(用于白盒和黑盒攻击)和连续优化(仅用于白盒攻击)来优化相机参数,具体方法如第3.3节所描述。网格搜索时,我们将ψ设置在[-45°, +45°]范围内,将θ设置在[-30°, +30°]范围内,创建了一个11×11的网格,其中ψ的步长为9°,θ的步长为6°。在连续优化方法中,我们采用了121次迭代的Adam优化器,学习率设置为0.01。关于这些超参数的消融研究和相应的执行时间已在补充材料中报告。我们所有的模型(针对不同的面部识别模型和场景)都在一台配备了NVIDIA RTX 3090 GPU的系统上进行了15个周期的训练,每个周期大约需要2天。在GNeRF方面,我们的实验采用了预训练的EG3D模型,并生成了分辨率为512×512的面部图像。GNeRF模型的输入噪声z具有512维,而我们映射网络MGaFaR的输入噪声n则具有16维。在利用真实面部图像(FFHQ)进行无监督学习时,我们假设这些图像的相机参数是正面视角。我们的实验源代码已经公开发布。
https://www.idiap.ch/paper/gafar
4.2. 分析
黑盒场景
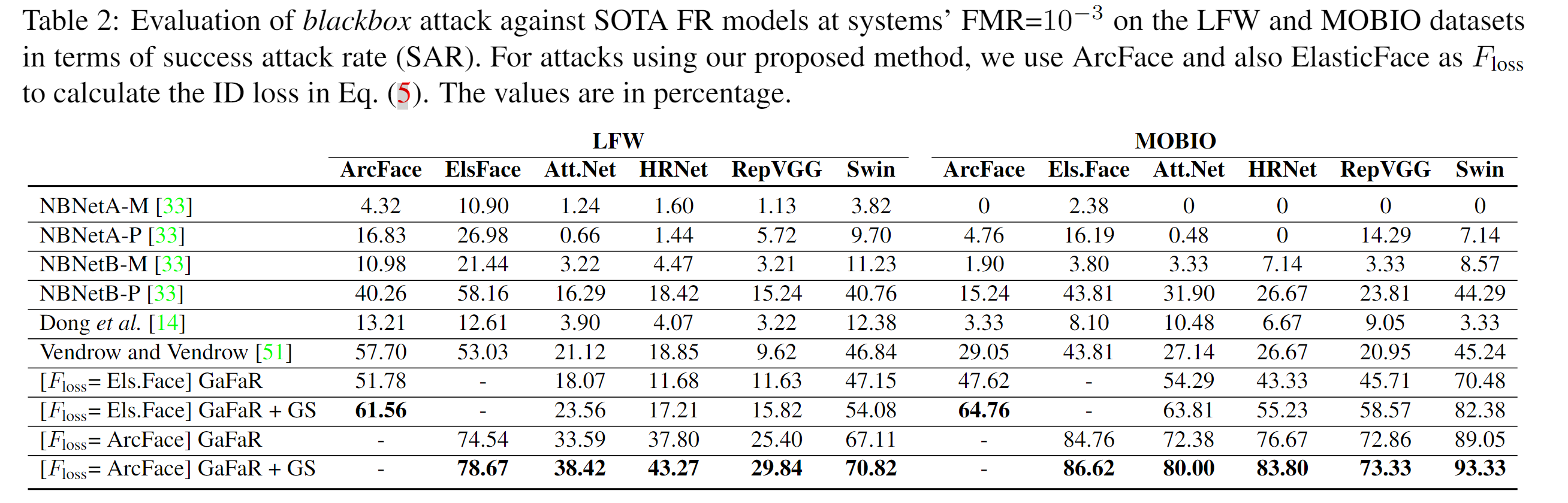
为了评估我们提出的在黑盒攻击中针对最新技术水平(SOTA)面部识别(FR)模型的方法,我们考虑使用ArcFace和ElasticFace作为损失函数(公式(5)中的ID损失)的计算基准。表2将我们提出的方法与文献中黑盒面部重建方法在错误匹配率(FMR)设定为\(10^{-3}\)时的系统攻击成功率(SAR)进行了比较。FMR设定为10^-2的类似结果已在补充材料中报告。表2显示,我们的方法(即GaFaR)在正面重建上的性能超过了文献中的现有方法。此外,相机参数优化(即GaFaR+GS)使我们的攻击性能比单纯的正面面部重建(即GaFaR)提高了最多17.14%。在使用ArcFace和ElasticFace作为Floss进行比较时,ArcFace模型的攻击性能更佳。这归因于ArcFace比ElasticFace具有更高的识别准确率。图3展示了使用ElasticFace模板在黑盒攻击中重建的样本面部图像(Floss使用的是ArcFace)。
白盒场景
表3展示了在白盒攻击中,针对配置了错误匹配率(FMR)为10^-3的面部识别(FR)系统的所提出方法的性能,以攻击成功率(SAR)来衡量。对于FMR = 10^-2的类似结果在补充材料中有报告。根据表3,所有这些面部识别模型都极易受到我们的攻击。此外,相机参数优化提升了GaFaR的性能。在比较网格搜索与连续优化时,结果显示,在相同迭代次数下,连续优化能够达到更好的性能。而且,将这些结果与面部识别模型的识别性能相比较(详细信息可见于补充材料),我们得出结论,识别准确度更高的模型更易受到攻击。对比表2和表3的结果,我们发现,当在损失函数中使用ArcFace作为Floss时,对于大多数情况,黑盒攻击的效果优于白盒攻击,这可以用ArcFace比其他面部识别模型具有更高的识别性能来解释。图4展示了在白盒攻击中基于ArcFace模板重建的样本面部图像。该图还呈现了不同姿势的重建面部图像的网格展示。

消融实验
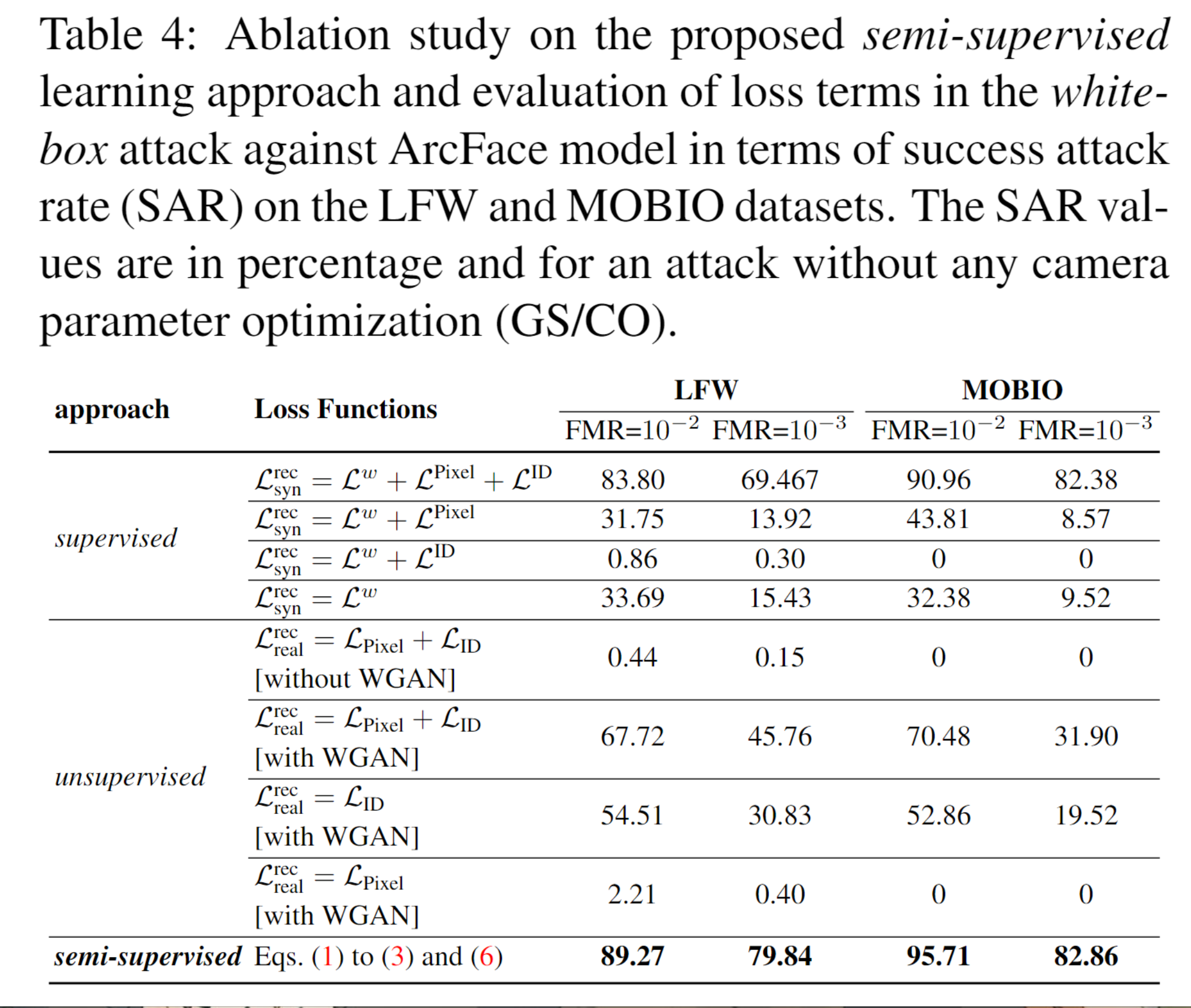
我们比较了我们提出的半监督学习方法与完全监督学习和完全无监督学习方法的效果。在每种情况下,我们也评估了每个损失函数的影响。此外,对于完全无监督学习方法,我们还评估了在我们方法中使用的GAN学习的效果。表4展示了在LFW和MOBIO数据集上针对ArcFace模型的白盒攻击中,系统错误匹配率(FMR)为\(10^{-2}\)和\(10^{-3}\)时,攻击成功率(SAR)的消融研究结果。这些结果显示,我们提出的半监督方法比完全监督学习和完全无监督学习方法取得了更好的性能。此外,我们的每个损失项都对性能有显著影响。特别是,在使用WGAN处理真实数据时,由于我们没有中间潜在代码的真实值,它帮助网络学习了GNeRF中间潜在空间W的分布。否则,映射网络生成的潜在代码将超出分布范围,因此GNeRF的生成部分将无法生成类似人脸的图像。
五、讨论
局限性
尽管我们的方法在实验中具有相当高的攻击成功率,但某些面部模板的重建图像却未能成功攻击系统。图5展示了在白盒攻击ArcFace时的样本失败情况。这些样本图像显示,失败的重建在生成深色皮肤和老年人面部时存在偏差。这种最终结果中的偏差可能是由于用于训练面部识别(FR)模型、GNeRF模型和我们的面部重建模型的各个数据集的内在偏差所引起的。除了偏差之外,通过比较表2和表3中对不同面部识别模型的攻击,我们发现识别性能较差的模型具有更低的攻击成功率和更多的失败案例。

道德考虑
这项工作提出了一种针对 FR 模型的 TI 攻击的新方法。 3D 重建脸部可用于生成 3D 面罩或 2D 打印照片,以针对 FR 模型进行演示攻击。 除了安全威胁之外,重建的人脸图像还可能泄露注册用户的重要隐私敏感信息,例如年龄、性别、种族等。我们不容忍使用我们的工作来攻击真实的 FR 系统。 事实上,这项工作的主要动机是展示FR系统中的这种脆弱性,并鼓励科学界开发和提出下一代安全且受保护的FR系统。 同样,数据保护法规,例如欧盟通用数据保护法规(EU-GDPR)[17],将生物特征数据视为敏感信息,并规定了保护它们的法律义务。 为此并减轻此类威胁,文献 [40,29,31,45] 中还提出了几种生物识别模板保护方案。 我们还应该注意到,所开展工作的项目已经通过了内部道德审查委员会(IRB)。
六、结论
在本文中,我们提出了一种新方法(称为 GaFaR),用于从面部模板生成 3D 面部重建,以针对 FR 模型进行 TI 攻击。 我们使用基于 GNeRF 的几何感知面部生成网络,并使用半监督学习方法训练从面部模板到 GNeRF 模型的中间潜在空间的映射。 为了训练我们的模型,我们使用了合成和真实的面部图像。 对于合成训练数据,我们拥有每个人脸图像的潜在代码,并且可以通过监督学习来训练我们的映射。 对于真实的训练数据,我们使用基于 GAN 的框架来学习潜在空间的分布。 在推理阶段,我们通过对相机参数的优化来找到提高攻击成功率的姿势。 我们在 LFW 和 MOBIO 数据集上针对 SOTA FR 模型的白盒和黑盒攻击评估了我们的方法。 据我们所知,本文是第一篇关于从面部模板(从 2D 人脸识别模型中提取)进行 3D 人脸重建的工作。